unicode
unicode 是基于通用字符集(Universal Character Set)的标准发展。Unicode的学名是”Universal Multiple-Octet Coded Character Set”,简称为UCS。UCS可以看作是”Unicode Character Set”的缩写,也就是说大家常听到的ucs2、ucs4都是其编码方式。
通用字符集(Universal Character Set,UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。
USC-2:使用两个字节编码,编码范围:U+00000000~U+0000FFFF
UCS-4:使用四字节编码,最高位必须为0 编码范围:U+00000000~U+7FFFFFFF,其中 U+00000000~U+0000FFFF和UCS-2是一样的
要注意,UCS-2和UCS-4只规定了代码点和文字之间的对应关系,并没有规定代码点在计算机中如何存储。规定存储方式的称为UTF(Unicode Transformation Format),其中应用较多的就是UTF-16和UTF-8了。
unicode设计原则
- Universality:提供单一、综合的字符集,编码一切现代与大部分历史文献的字符。
- Efficiency:易于处理与分析。
- Characters, not glyphs:字符,而不是字形。
- Semantics:字符要有良好定义的语义
- Plain text:仅限于文本字符
- Logical order:默认内存表示是其逻辑序
- Unification:把不同语言的同一书写系统(scripts)中相同字符统一起来。
- Dynamic composition:附加符号可以动态组合。
- Stability:已分配的字符与语义不再改变。
- Convertibility:Unicode与其他著名字符集可以精确转换。
编码方式
Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位(code point)。码位就是可以分配给字符的数字。码位通常写成 U+ABCD 的格式。
- 分为17个平面,每个平面编码范围:0x0000-0xFFFF,最终的编码范围:0x0000-0x10FFFF,也就是说用第3个字节的前4bit位进行平面标记
- 第0平面,也就是第三字节0,编码范围:0x000000到0x00FFFF的码位,称之为基本多语言平面(Basic Multilingual Plane, BMP),此范围的码位对应了绝大部分的字符编码
- 第1到第16平面称之为辅助平面(Supplementary Planes)
- 其中第0平面有一部分码位不映射到任何字符,即0xD800-0xDFFF,1101 1000 0000 0000到1101 1111 1111 1111
统一码的编码方式与ISO 10646的通用字符集概念相对应。目前实际应用的统一码版本对应于UCS-2,使用16位的编码空间。也就是每个字符占用2个字节。这样理论上一共最多可以表示2^16(即65536)个字符。基本满足各种语言的使用。实际上当前版本的统一码并未完全使用这16位编码,而是保留了大量空间以作为特殊使用或将来扩展。
上述16位统一码字符构成基本多文种平面。最新(但未实际广泛使用)的统一码版本定义了16个辅助平面,两者合起来至少需要占据21位的编码空间,比3字节略少。但事实上辅助平面字符仍然占用4字节编码空间,与UCS-4保持一致。未来版本会扩充到ISO 10646-1实现级别3,即涵盖UCS-4的所有字符。UCS-4是一个更大的尚未填充完全的31位字符集,加上恒为0的首位,共需占据32位,即4字节。理论上最多能表示2^31个字符,完全可以涵盖一切语言所用的符号。
utf-16
各种资料都说,utf-16是unicode的父集。其实,这个应该已经算是过时了。只能说在基本多语言平面,utf-16的编码值和unicode码位值相同,在辅助平面就不是了,utf-16的编码和unicode码位之前存在一个转换关系。具体计算过程如下:
- 如果unicode码值小于等于U+FFFF(基本多语言平面的码位),则unicode码位的值就是对应的UTF-16的编码值
- 对于unicode码值大于U+FFFF的码位(辅助平面的码位),被编码为一对16比特长的码元(即32bit,4Bytes),称作代理对(surrogate pair)
- 码位减去0x10000,得到的值的范围为20比特长的0..0xFFFFF.
- 高位的10比特的值(值的范围为0..0x3FF)被加上0xD800得到第一个码元或称作高位代理(high surrogate),值的范围是0xD800..0xDBFF.由于高位代理比低位代理的值要小,所以为了避免混淆使用,Unicode标准现在称高位代理为前导代理(lead surrogates)。
- 低位的10比特的值(值的范围也是0..0x3FF)被加上0xDC00得到第二个码元或称作低位代理(low surrogate),现在值的范围是0xDC00..0xDFFF.由于低位代理比高位代理的值要大,所以为了避免混淆使用,Unicode标准现在称低位代理为后尾代理(trail surrogates)。
示例如下:

utf-8
utf-8算是和utf-16编码有点类似,但又有较大区别, 其从最高位开始,连续为1的bit位个数,作为当前是第几个字节编码的标准,连续所有字节的bit位连接起来即为unicode码值。具体如下:
- 在U+0080的以下字符都使用内含其字符的单字节编码。这些编码正好对应7比特的ASCII字符
- 在其他情况,有可能需要多达4个字符组来表示一个字符。这些多字节的最高有效比特会设置成1,以防止与7比特的ASCII字符混淆,并保持标准的字节主导字符串运作顺利
转换表格如下:
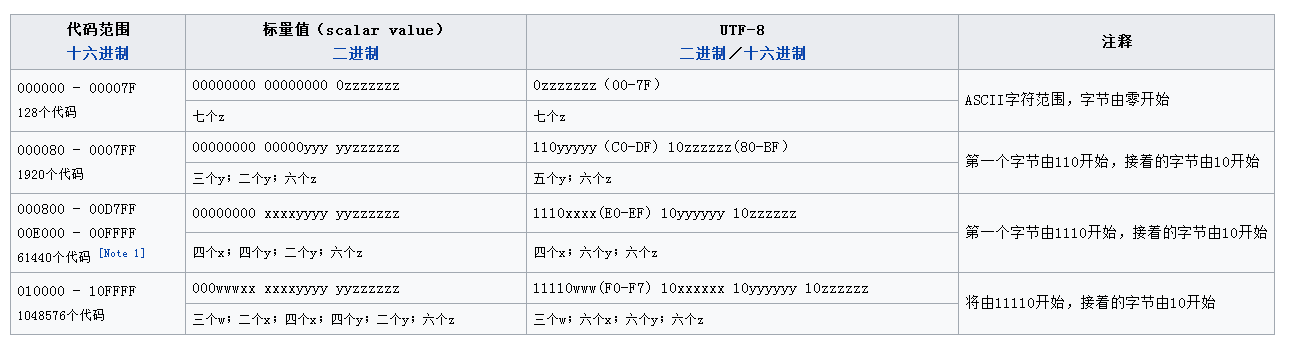
所以我们很容易就能够对一个utf-8的字节流进行解码,具体如下:
- 对于UTF-8编码中的任意字节B,如果B的第一位为0,则B独立的表示一个字符(ASCII码);
- 如果B的第一位为1,第二位为0,则B为一个多字节字符中的一个字节(非ASCII字符);
- 如果B的前两位为1,第三位为0,则B为两个字节表示的字符中的第一个字节;
- 如果B的前三位为1,第四位为0,则B为三个字节表示的字符中的第一个字节;
- 如果B的前四位为1,第五位为0,则B为四个字节表示的字符中的第一个字节;
关于mysql与utf-8
在一些老的系统和软件里面都使用3字节存储utf-8编码,也就是说都只对基本多语言平面的unicode字符编码。其中包含mysql。在mysql 5.5.3之前,无法存储0x10000-0x10FFFF的编码,mysql 5.5.3之后,可以使用utf8mb4作为字符集编码方式。虽然使用此方式能够正,但不建议在外部的环境中使用,具体如下:
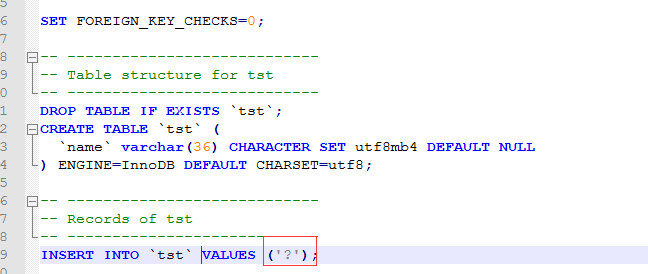
数据表结构:
CREATE TABLE `tst` (
`name` varchar(36) CHARACTER SET utf8mb4 DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
使用navicat执行sql语句:
SELECT * FROM tst WHERE `name`='𠃍'
此时会提示出错: Illegal mix of collations (utf8mb4_general_ci,IMPLICIT) and (utf8_general_ci,COERCIBLE) for operation ‘=’
在sqlyog中亦是如此
使用navicat导出表数据,结果如下(sqlyog也是如此):
网上也有人在反应此类问题。
另外,通过程序insert数据时,连接字符串也必须要指定字符集为utf8mb4才行,否则也是无法正常执行的
DataSource=127.0.0.1;port=3307;UserId=a;Password=a;Database=ta;Allow Zero Datetime=true;charset=utf8mb4;
指定连接字符的charset为utf8、utf8mb4都可以正确查询得到结果
总结一下:
- 数据库连接字符串必须要设置为utf8mb4
- 字段必须要设置为utf8mb4
- 使用工具执行sql时,不要包含特殊字符
- 不要使用普通工具进行包含特殊字符的表的数据的导入导出
最后,如非必要,不建议设置数据库字段为utf8mb4编码
绘文字(表情符号)的过滤
不同的编程语言处理代码不一致,但基本原理都一样。通过unicode码表找到所有emoji字符,然后硬编码过滤(由于emoji是散落在unicode各平面,并不是完全连续的,所以正则过滤不准确。)
现已完整实现了golang和C#版本的绘文字过滤,其他语言可进行参考(大部分语言简单修改即可使用):emojifilter
其中,C#版本的利用了C#在内存中采用了utf-16编码的特性的
emoji码表可参考:unicode的emoji汇总